
Soft Delete 정책과 @SQLRestriction에 대한 고찰
DESCRIPTION
여행 기록 관리 플랫폼 서비스에서 사용자 데이터 삭제 정책 중 Soft Delete 정책을 도입하기로 하였다. @SQLRestriction 어노테이션을 사용하여 엔티티 조회 시 쿼리 내 삭제된 사용자를 제외하는 조건문을 자동으로 추가하였다. 해당 프로젝트를 진행 중 Soft Delete 정책과 @SQLRestriction을 사용하며 겪었던 문제와 개인적인 생각을 정리하고자 한다.
서론
여행 기록 관리 플랫폼 서비스를 개발하며 사용자 삭제 정책에 대해 논의를 하며 Soft Delete(논리 삭제) 정책을 도입하기로 하였다. Soft Delete 정책은 특정 엔티티 삭제 시 해당 엔티티를 데이터베이스 내에서 완전히 삭제하는 것이 아니라 삭제 여부를 나타내는 컬럼을 별도로 생성해 컬럼 값을 통하여 삭제 여부를 확인하는 방법이다.
boolean 값을 통하여 삭제 여부를 확인할 수도 있지만, LocalDateTime (=timestamp) 타입의 필드를 정의하여 탈퇴 후 7일이 지난 사용자는 모든 데이터를 완전 삭제하는 방식으로 삭제 로직을 구상하였다.
또한, JPA의 구현체인 hibernate에서는 @SQLDelete 어노테이션을 통해 엔티티 삭제 시 실행할 쿼리를 별도로 지정하여 Soft Delete를 쉽게 구현할 수 있다. 이후, 삭제된 엔티티는 조회에서 제외되어야 한다. 따라서, @SQLRestriction 어노테이션을 통하여 조회 쿼리 내 WHERE ... 절을 자동으로 추가하여 조회에서 제외할 수 있다. 코드는 아래와 같다.
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity(name = "users")
@DynamicUpdate
@SQLRestriction("deleted_at IS NULL")
@SQLDelete(sql = "UPDATE users SET deleted_at = NOW() WHERE id = ?")
public class User extends BaseTimeEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
/* ... */
@Column(name = "deleted_At")
private LocalDateTime deletedAt;
/* ... */
}
처음에는 어노테이션을 활용하여 Soft Delete된 사용자를 조회에서 제외할 수 있다는 점이 되게 편리하다고 생각하였다.
그러나, 프로젝트 규모가 커지고 추가된 기능이 많아지며 ‘삭제된 사용자를 포함하여 모든 사용자를 조회’해야하는 소요가 발생하였다. 이 때, @SQLRestriction 어노테이션에 의해 WHERE deleted_at IS NULL 조건이 조회 쿼리에 자동으로 추가되어 조회가 제대로 진행되지 않는 문제가 발생하였다.
해당 문제를 통해 “Soft Detete 정책에서 @SQLRestriction을 사용하는 것이 과연 좋기만한가?”라는 의문이 들기 시작하였다. 해당 포스팅에서는 이에 대한 개인적인 생각과 QueryDSL에서 네이티브 SQL을 사용하여 문제를 해결한 경험을 풀어보고자 한다.
본론
Soft Delete 정책과 @SQLRestriction을 도입하여 생기는 문제
Soft Delete와 @SQLRestriction을 사용하여 생기는 문제는 조회 쿼리에 자동으로 WHERE deleted_at IS NULL 제약 조건이 자동으로 추가되기 때문에 발생하게 된다.
1. @Query 사용으로 인한 문제
Spring Data JPA는 JPA의 구현체인 hibernate를 사용하기 때문에 조회 쿼리에 자동으로 Soft Delete된 사용자를 제외하는 조건을 포함하기 때문에 일반적인 네이밍 메서드를 통한 조회 시에는 탈퇴한 사용자 조회가 불가능하다.
프로젝트를 진행하며 탈퇴한 사용자 정보도 필요했던 경우는 다음과 같다.
- 어드민 관련 기능에서 전체 사용자를 조회하여야 할 때
- 닉네임 설정 시 탈퇴된 사용자의 닉네임과 일치하지 않는지 체크 (탈퇴 철회 고려)
- 탈퇴된 사용자와 연관되어 있는 엔티티를 조회할 떄
위와 같은 상황에서 탈퇴한 사용자의 정보가 필요하였지만 일반적인 네이밍 메서드로는 조회가 불가능하였다. 따라서, 네이티브 SQL을 사용하여 조회를 하여야지만 데이터베이스로 직접 SQL 쿼리를 보내 @SQLRestriction 설정을 피할 수 있었다.
이 과정에서 @Query 어노테이션을 통한 쿼리 작성 시 컴파일 시점에 오류 확인이 불가하거나 조인을 통한 조회 시 중복된 컬럼으로 인해 특정 엔티티의 모든 컬럼을 select 절에 모두 적어줘야하는 등의 문제가 있었다. 프로젝트의 규모가 증가하고 요구 기능이 많아지며 해당 문제는 큰 불편함으로 다가왔다.
2. 도메인 서비스 클래스 응집도 저하
앞서, 어드민 관련 기능(api)에서는 전체 사용자를 요구한다고 하였다. 이와 대비해 일반적인 사용자를 대상으로한 기능에서는 탈퇴된 사용자 정보는 필요하지 않는 경우가 많다.
즉, Presentation Layer에서 하나의 도메인(사용자)에 대한 요구 기능이 다르기 때문에 사용자 도메인 서비스를 분리하거나 클래스의 크기가 커져 응집도가 저하되는 문제가 발생할 수 있을 것이다.
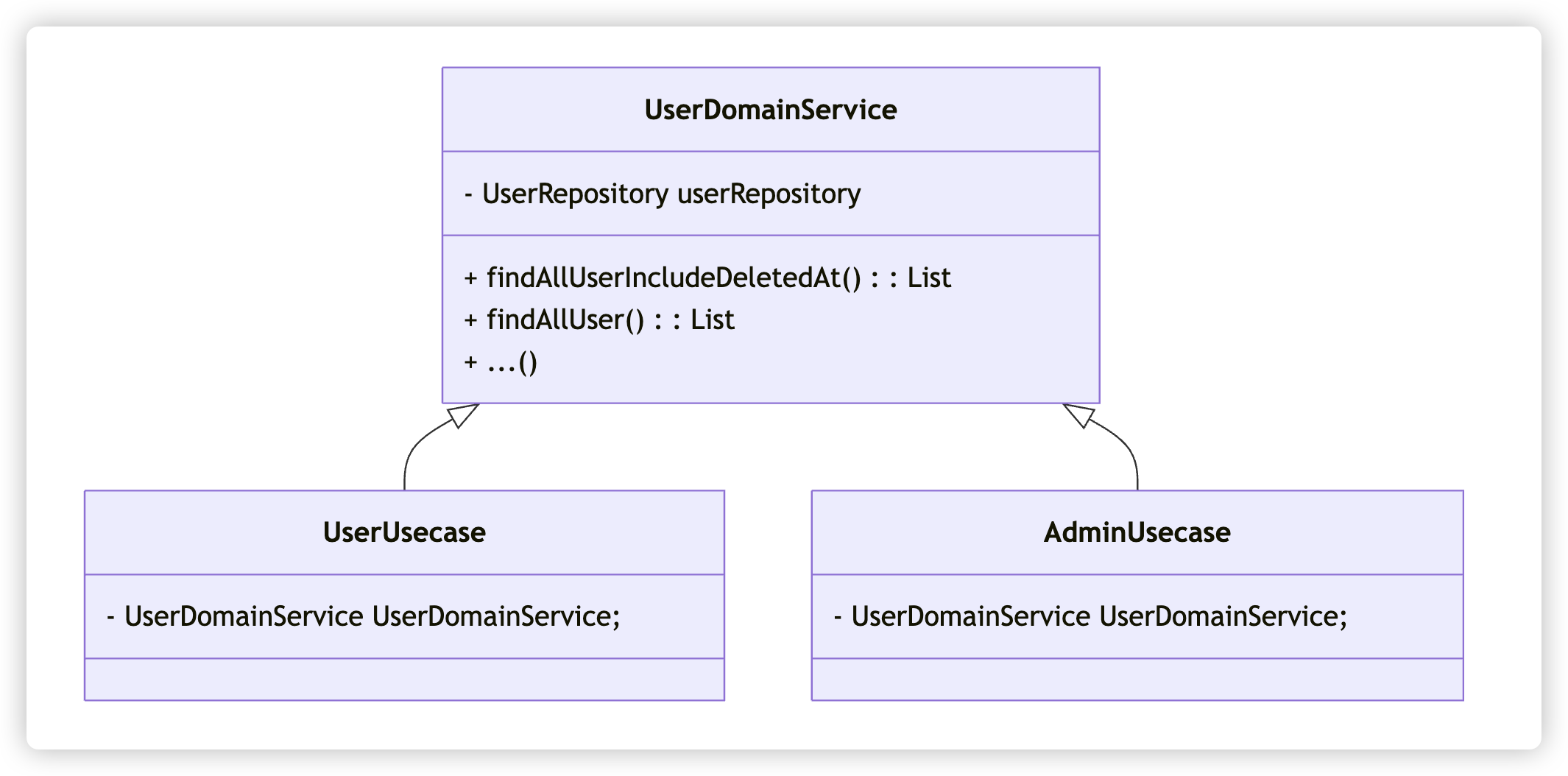
위와 같이 사용자 도메인 서비스를 의존하고 있는 각 유즈케이스에서는 요구하는 기능이 다르며 @SQLRestriction으로 인해 UserRepository 내에 @Query를 설정한 별도의 메서드를 호출하여야한다. 따라서, 같은 도메인 서비스 내에서도 사용하는 메서드가 분리되는 상황이 발생한 것이다.
프로젝트 규묘가 작다면 해당 문제는 하나의 사용자 도메인 서비스 내에 코드가 응집되어 있어 큰 문제가 없는 것처럼 보일 것이라 생각한다. 그러나, 기능 요구사항이 많아지면 자연스럽게 도메인 서비스 내의 메서드도 증가할 것이다. 다른 유즈케이스에 의해 사용되는 메서드가 많아질수록 클래스의 크기는 증가할 것이며 이는 응집도의 저하라고 생각한다.
그렇다면, 프로젝트 규모가 커질 경우 도메인 서비스 자체를 분리하는 방법을 생각해볼 수 있다.
그러나 해당 경우에는 Presentation 레이어의 요구사항이 Domain 레이어까지 영향을 미친 것이라 볼 수 있으며, 고수준의 서비스가 저수준 서비스에 의존하게 되는 의존성 역전 원칙을 위배하는 경우로도 볼 수 있을 것이다.
3. 저장소 클래스 내에 추가 의존성 필요
추가적으로 해당 프로젝트에서는 Spring Data JPA와 QueryDSL을 동시에 사용하였기에 저장소 컴포넌트가 여러 개 존재한다.
public interface UserRepository extends JpaRepository<User, Long>, CustomUserRepository {
Optional<User> findByFcmToken(String fcmToken);
List<User> findAllByIdIn(List<Long> ids);
}
public interface CustomUserRepository {
Optional<User> findUserIncludeDeletedByPlatformAndPlatformId(String platform, String platformId);
Optional<User> findUserIncludeDeletedById(Long id);
Optional<User> findUserIncludeDeletedByNickname(String nickname);
Optional<User> findUserIncludeDeletedByUsername(String username);
List<Long> findDeletedUserIdBefore(LocalDate date);
boolean existsIncludeDeletedByUsername(String username);
boolean existsIncludeDeletedByNickname(String nickname);
boolean existsIdIncludeDeletedByEmail(String email);
void deleteHardAllByIdIn(List<Long> ids);
}
@RequiredArgsConstructor
public class CustomUserRepositoryImpl implements CustomUserRepository {
private final SQLTemplates sqlTemplates;
private final JPAQueryFactory jpaQueryFactory;
@PersistenceContext
private final EntityManager entityManager;
private final QUser user = QUser.user;
private final EntityPath<User> USER_ENTITY_PATH = new EntityPathBase<>(User.class, "users");
private final EntityPath<OAuth> OAUTH_ENTITY_PATH = new EntityPathBase<>(OAuth.class, "oauth");
private static final class USER_COLUMN {
private USER_COLUMN() { }
private static final String ID = "id";
private static final String NICKNAME = "nickname";
private static final String USERNAME = "username";
private static final String DELETED_AT = "deleted_at";
private static final String EMAIL = "email";
}
private static final class OAUTH_COLUMN {
private OAUTH_COLUMN() { }
private static final String USER = "user_id";
private static final String PLATFORM = "platform";
private static final String PLATFORM_ID = "platform_id";
}
@Override
public Optional<User> findUserIncludeDeletedByPlatformAndPlatformId(String platform, String platformId) {
JPASQLQuery<Tuple> jpaSqlQuery = new JPASQLQuery<>(entityManager, sqlTemplates);
return Optional.ofNullable(
jpaSqlQuery
.select(USER_ENTITY_PATH)
.from(USER_ENTITY_PATH)
.innerJoin(OAUTH_ENTITY_PATH)
.on(Expressions.numberPath(Long.class, USER_ENTITY_PATH, USER_COLUMN.ID)
.eq(Expressions.numberPath(Long.class, OAUTH_ENTITY_PATH, OAUTH_COLUMN.USER)))
.where(
Expressions.stringPath(OAUTH_ENTITY_PATH, OAUTH_COLUMN.PLATFORM)
.eq(platform),
Expressions.stringPath(OAUTH_ENTITY_PATH, OAUTH_COLUMN.PLATFORM_ID)
.eq(platformId)
)
.fetchOne()
);
}
/* ... */
@Override
public void deleteHardAllByIdIn(List<Long> ids) {
jpaQueryFactory
.delete(user)
.where(user.id.in(ids)).execute();
}
}
위와 같이 JpaRepository를 구현하고, QueryDsl을 사용하기 위하여 CustomUserRepository 인터페이스를 정의하고 이를 구현하는 구현체를 사용하는 등 여러 개의 저장소가 만들어지게 된다.
그러나 해당 방법 자체로는 응집도가 저하된다고 생각하지는 않는다.
위와 같이 커스텀 저장소 인터페이스를 저장하고, 기술에 따라 여러가지 구현체를 정의하여 하나의 리포지토리를 통해 사용 가능하게 하는 것은 프래그먼트 기반 프로그래밍 모델(Fragment-based Programming model로 Spring Data JPA 공식 문서에서도 언급하는 방법이다.
그렇다면, 해당 절에서 언급하는 저장소 클래스의 응집도 저하는 CustomUserRepositoryImpl 내에 SQLTemplates와 JPAQueryFactory를 동시에 사용하는 부분이다.
기본적으로 QueryDSL에서도 hibernate를 사용하기 때문에 @SQLRestriction에 의해 제약을 받는 것은 동일하다. 따라서, QueryDSL에서도 Navtive SQL을 사용하여 해당 제약을 피하는 방법으로 코드를 작성하여야 한다.
QueryDSL 공식 문서의 2.1.15. JPA 쿼리에서 네이티브 SQL 사용하기 부분을 보면 특정 데이터베이스의 SQL을 나타내는 SQLTemplates 빈을 등록하고 EntityManger와 함께 JPASQLQuery의 인자로 사용하여 네이티브 SQL을 사용하는 방법을 기술하고 있다.
@Configuration
public class QueryDslConfig {
/* ... */
@Bean
public SQLTemplates sqlTemplates() {
return new MySQLTemplates();
}
}
해당 프로젝트에서는 RDB로 MySQL을 사용하였기 때문에 MySQLTemplates를 빈으로 등록하였다.
따라서, CustomUserRepositoryImpl 내에서도 조회하는 쿼리는 JPASQLQeury를 사용하여 구현하였다. 그러나, 사용자 엔티티 완전 삭제의 경우에는 JPA 자체를 사용하더라도 데이터베이스로 바로 삭제 쿼리가 전달되기 때문에 QueryDSL에서는 Native SQL을 사용하여 삭제 쿼리를 보내는 방법이 정의되어 있지 않다. 따라서, QueryDSL을 사용할 때 일반적으로 사용하는 JPAQueryFactory를 사용하더라도 삭제가 진행된다.
즉, JPAQueryFacotry는 사용자 완전 삭제만을 위해서 해당 클래스에서 의존하게 되는 것이다.
다른 방법으로도 설계는 가능하겠지만, 필자는 차후 QueryDSL 사용에 중점을 맞추어 코드를 작성하였기 때문에 위와 같이 삭제 메서드가 동일한 저장소 클래스 내에 위치하게 되었다.
만약, Spring Data JPA가 아닌 QueryDSL만 사용하는 프로젝트일 경우에는 저장소 클래스 내에 여러 의존성 및 Native SQL을 사용하기 위한 기타 코드들이 정의되게 되어 가독성 자체가 저하될 가능성도 존재한다. 물론 해당 방법도 프로그래먼트 기반 프로그래밍 모델 기법에 의해 별도로 분리한다면 해결할 수 있는 문제라고 생각한다.
Soft Delete와 @SQLRestriction을 같이 사용하는게 무조건 좋을까?
위와 같은 이유들로 인하여 “Soft Delete 정책과 @SQLRestriction을 사용하는 것이 무조건 좋을까?”라는 질문이 시작되었다.
프로젝트 규모나 요구사항에 따라 @SQLRestriction을 잘 사용한다면 중복적인 쿼리 작성 필요를 줄여 작업 속도를 크게 높일 수 있을 것이다. 그러나, 프로젝트 규모가 커지고 여러 가지 요구사항에 따라 위와 같은 상황이 발생한다면 @SQlRestriction이 기타 컴포넌트들에도 영향을 미치게 되어 추가적인 비용을 요구하게 되기도 한다. 이렇듯 적절한 트레이드 오프 관계를 잘 고려하여 도입을 논의하는 것이 좋다고 생각한다.
만약 @SQLRestirction 어노테이션을 제거한다면 탈퇴된 사용자를 제외한 조회 시 매번 조건문을 추가하여야하는 것에 대해서는 QueryDSL의 동적 쿼리 생성 기능을 활용한다면 이 수고를 덜어줄 수 있을 것이라 생각한다.
@RequiredArgsConstructor
public class CustomUserRepository implements CustomUserRepository {
private final JPAQueryFactory jpaQueryFactory;
private final QUser user = QUser.user;
@Override
public List<User> findAllUser(boolean isIncludeDeleted) {
return jpaQueryFactory
.select(user)
.from(user)
.where(isDeleted(isIncludeDeleted))
.fetch();
}
private BooleanExpression isDeleted(boolean isIncludeDeleted) {
return isIncludeDeleted ? null : user.deletedAt.isNull();
}
}
위와 같이 BooleanExpression을 사용하여 삭제된 isIncludeDeleted = true일 경우 해당 조건문을 포함시키지 않아 모든 사용자를 조회하고, false일 경우 deletedAt 필드가 null인 탈퇴하지 않은 사용자만 조회되도록 설계할 수 있을 것이다.
결론
스프링 프로젝트를 진행하다보면 여러가지 편리한 어노테이션의 도움을 받을 때가 많다. 생산성을 높여주며 불필요한 작업을 줄여주어 작업의 속도를 높여주기 때문이다.
그러나, 이와 같은 문제점이 발생하기도 한다. 이미 프로젝트가 시작된 다음 해당 어노테이션에 의해 영향받는 코드를 요구사항에 의해 다시 리팩토링하는 과정에서는 비용이 발생한다.
따라서, 초기 설계 단계부터 특정 어노테이션이 미칠 영향을 잘 고려하는 것이 중요하다. 물론 프로젝트를 진행하며 이와 같은 상황을 직접 경험해보아야만 이러한 트레이드 오프를 잘 고려할 수 있는 능력이 생기는 것이라 생각한다.