
findBy vs exsitsBy
DESCRIPTION
필자는 다른 사람들의 프로젝트을 열람하던 중 레코드 존재 여부 확인 과정에서 사용하는 메서드에서 의문점을 느끼게 되었다. 해당 포스팅에서는 레코드 존재 여부 확인 과정에서 사용하는 메서드에 따른 SQL 쿼리문의 차이와 그로 인한 성능 차이를 비교하고자 한다.
서론
필자는 다른 사람들의 프로젝트를 열람하여 새로운 지식을 얻고는 한다. 최근 레코드(엔티티) 조회 여부를 확인하는 메서드에서 아래와 같이 정의된 메서드를 본 적이 있다.
UserService {
...
public boolean isExist(String email) {
return userRepository.findByEmail(email).isPresent();
}
}
필자는 해당 메서드를 보면 Spring Data Jpa 내에 존재하는 existsByEmail(String email)이 아니라 findByEmail(String email)을 사용하는 것 인지에 대한 궁금증이 생겼다.
따라서 두 쿼리 메서드에서 생성하는 쿼리의 차이가 있을 것이라 생각하였고, 해당 부분에 대해 찾아보고 실습을 통하여 성능 비교를 진행하였다. 해당 포스팅에서는 위 테스트를 통해 알아본 발생 쿼리, 성능 차이에 대한 내용을 다루고자 한다.
이번 테스트에 사용환 환경은 다음과 같다
- SpringBoot 3.4.3
- MySQL (Docker mysql:latest)
또한, 10,000개의 Team 레코드에서 조회 성능 차이를 비교하기 위해 아래와 같은 Team 엔티티 10,000개가 데이터베이스 내에 삽입되어 있는 상태이다.
@Entity(name = "team")
@NoArgsConstructor
@AllArgsConstructor
public class Team {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@Builder
public Team(String name) {
this.name = name;
}
}
findById vs existsbyId
우선 PK를 통한 존재 여부 조회 성능을 비교해보고자 한다. PK의 경우 인덱싱 처리가 되어있으며, 현재 레코드가 10,000개 뿐이기에 id로 1L 값을 가지는 레코드 존재 여부 검색만 진행하였다.
@Test
@DisplayName("findById")
void findById_테스트() {
StopWatch stopWatch = new StopWatch("findById");
stopWatch.start();
Team team = teamRepository.findById(1L)
.orElseThrow(() -> new RuntimeException("Team not found."));
stopWatch.stop();
System.out.println(stopWatch.prettyPrint(TimeUnit.MILLISECONDS));
}
@Test
@DisplayName("existsById")
void existsById_테스트() {
StopWatch stopWatch = new StopWatch("existsById");
stopWatch.start();
boolean isExists = teamRepository.existsById(1L);
stopWatch.stop();
System.out.println(stopWatch.prettyPrint(TimeUnit.MILLISECONDS));
}
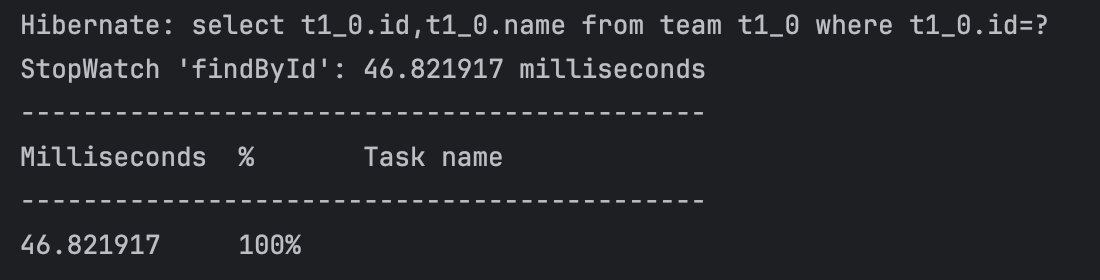
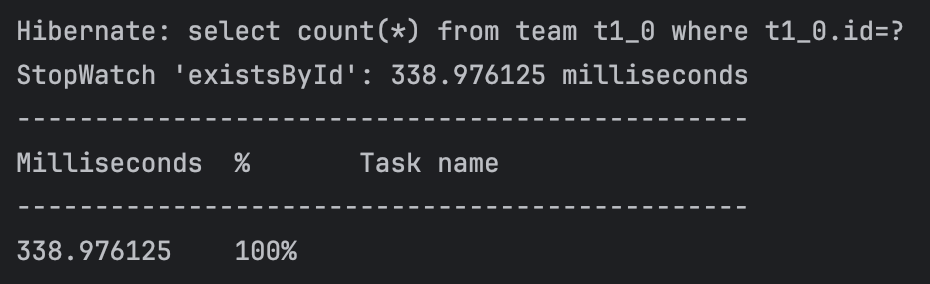
실행 결과는 다음과 같다.
| findById() | existsById() |
|
|
실행 결과에서 알 수 있듯이 findById에 대비해 existsById는 7배 이상의 시간이 소요된다. 이 시간의 차이는 실행되는 SQL 쿼리문의 차이에서 기인한 것이다.
id는 레코드의 PK로서 유일한 값이며 기본적으로 인덱싱이 되어있다. select 쿼리를 통하여 특정 값을 조회하였을 때, 조건에 부합한 값을 찾는다면 해당 값이 유일한 값이므로 해당 레코드를 바로 리턴한다. 이는 findByName과 같은 유니크하지 않은 일반 컬럼(필드)에 대비하여 속도의 차이가 더욱 극명하게 나는 이유이다.
existsById는 count(*) 쿼리를 사용한다. 즉, 조건에 부합하는 모든 레코드를 탐색하기 때문에 조회 상 성능이 저하된다. 현재는 10,000개의 데이터만 존재하기 떄문에 그 차이가 그리 크지 않지만 레코드의 크기가 커진다면 응답 시간이 증가해 사용자 경험이 더욱 저하될 것 이다.
Spring Data Jpa의 SimpleJpaRepository 클래스를 확인해보면 existsById()의 동작을 알 수 있다.
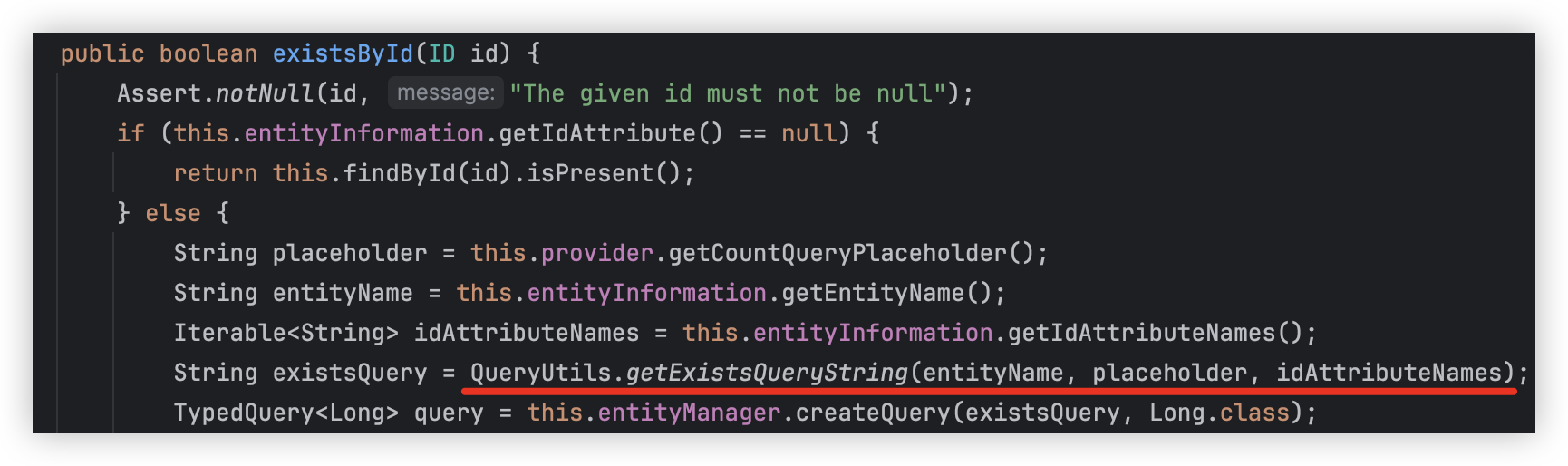
우리가 주목해야할 부분은 QueryUtils.getExistsQueryString(...)이다. 해당 메서드에서 실행할 쿼리를 가져오는 것이다. 그렇다면 해당 메서드를 확인해보자.

로그에서 보았던 count 쿼리 포맷을 확인할 수 있다.
existsById()는 왜 count(*) 쿼리를 사용하는가?
그렇다면, 굳이 existsById()는 왜 성능이 좋지 못한 count(*) 쿼리를 사용하는 것일까?
findById() vs exsitsById()에 관한 글이나 자료들은 많았지만, count(*) 쿼리를 생성하는 이유에 대한 자료들은 찾을 수가 없었다. 따라서, Spring Data Jpa의 깃허브에 이슈를 통하여 질문을 남기기로 하였다.
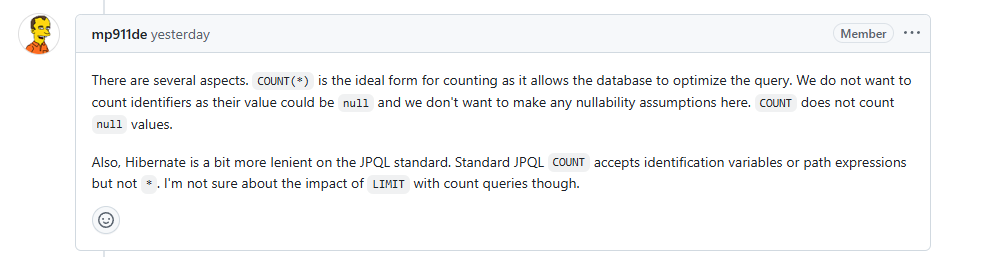
Spring Data의 Lead를 맡으시는 Mark Paluch 께서 답변을 해주셨다. 답변 내용을 요약하자면 아래와 같다.
existsById()가 count(*) 쿼리를 사용하는 것에는 여러 가지 이유가 있지만, count(*)가 카운팅에 있어 가장 이상적인 형태로, 데이터베이스가 쿼리를 최적화할 수 있도록 해준다고 한다. 또한, Spring Data Jpa에서도 식별자(id)를 카운팅하고 싶지는 않지만, 식별자가 null일 수도 있다는 가능성 때문에 이 가능성에 대한 어떠한 가정도 허용하지 않겠다는 것이다.
findByName vs existsByName
먼저 두 메서드를 비교히기에 앞서 JpaRepository에 정의된 메서드는 아래와 같다.
public interface TeamRepository extends JpaRepository<Team, Long> {
List<Team> findByName(String name);
boolean existsByName(String name);
}
name 필드는 유일성을 보장하지 않는 필드이다. findByName()의 경우 List 형태로 값을 받아온다.
실행 결과는 다음과 같다.
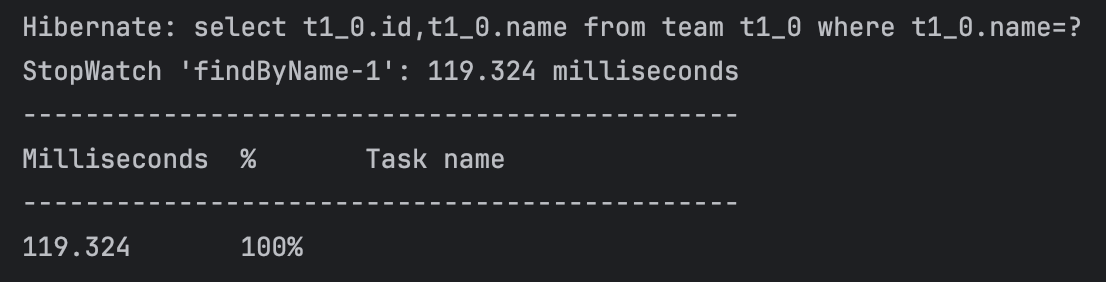
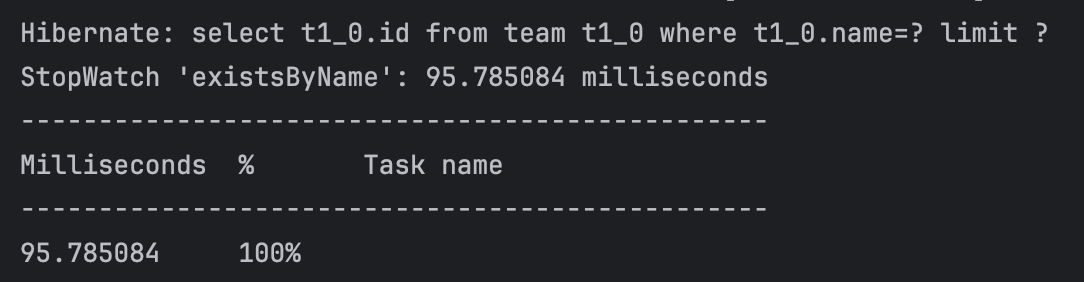
| findByName() | existsByName() |
|
|
위 결과에서 알 수 있듯이, 일반 필드의 경우에는 existByName() 메서드의 성능이 더욱 좋은 것을 확인할 수 있다. 실행된 쿼리를 확인하면 그 차이의 이유를 알 수 있다. findByName()의 경우, 컬럼 내 일치하는 값을 가진 모든 레코드들을 찾아 반환해야한다. 그러나, existsByName()의 경우 ‘존재 여부’만 확인하는 목적이기에 Spring Data Jpa에서 자체적으로 limit 1 제약 조건을 추가하여 조건과 일치하는 값 존재 시 즉시 반환하게 되어 성능이 더욱 좋다.
만약, @Query 어노테이션과 Native Query을 통해 findByName()에 limit 1 제약 조건을 추가한다면 어떻게 될까?
public interface JpaTeamRepository extends JpaRepository<Team, Long> {
@Query(value = "SELECT * FROM team t WHERE t.name = :name LIMIT 1", nativeQuery = true)
Optional<Team> findByName(String name);
boolean existsByName(String name);
}
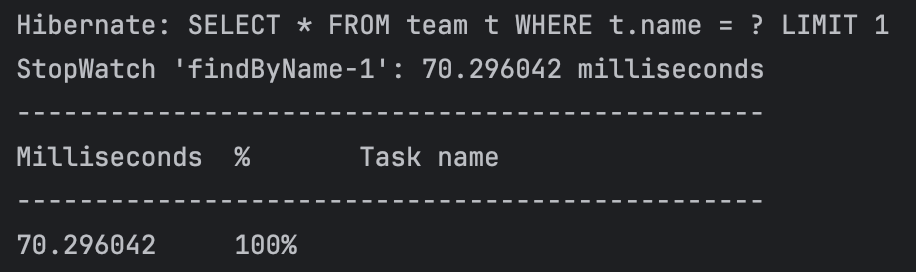
앞서 보았던 existsByName() 메서드로 인해 생성된 쿼리와 동일한 것을 알 수 있다. 그러나, @Query 어노테이션 사용 시 반환된 값이 영속성 컨텍스트 저장이 되지 않는 다는 것을 인지하여야 한다. 또한, 유니크하지 않은 값은 PK 값이 될 수 없다. 즉, PK가 아닌 컬럼에 대해서는 existsBy__() 메서드를 사용하는 것이 더욱 좋다고 생각한다.
또한, 특정 컬럼을 통해 존재 여부를 확인하는 대부분의 경우에는 해당 컬럼은 유니크한 경우가 많다고 생각한다. MySQL의 경우 unique 제약 조건이 존재하는 컬럼에 대해서는 자동으로 인덱스를 생성한다. 따라서, 엔티티 설계 시 해당 컬럼의 유일성을 고려하여 unique 제약 조건을 추가한다면, 인덱스를 통해 조회 성능을 조금이라도 더 올릴 수 있다라고 생각한다.
마무리
PK 컬럼을 통한 조회의 경우, Spring Data Jpa의 내부 동작에 의하여 existsById()는 count(*) 쿼리를 날리기 때문에 응답 시간이 느리다는 것을 확인하였다. 데이터의 양이 더 커질 경우 이는 전체적인 성능에 극심한 영향을 미칠 것이다. 따라서, id 필드를 통한 엔티티의 존재 여부 확인 시 아래와 같은 구조로 사용하는 것이 좋다고 생각한다.
@Service
@RequiredArgsConstructor
UserService {
private final UserRepository userRepository;
public void isExist(Long id) {
return userRepository.findById(id).isPresent();
}
}
PK 컬럼을 제외한 다른 컬럼의 경우, 엔티티 존재 여부 확인의 목적이라면 eixstsById() 사용하는 것이 더욱 적절하다고 생각한다. 일반 컬럼에 대해서는 조회에 대한 로직보다는 엔티티 설계 시 유일성을 잘 고려하여 unique 제약 조건을 추가함으로써 데이터베이스에서 제공하는 인덱싱의 이점을 잘 사용하는 것이 더욱 중요하다고 생각한다.
해당 포스팅에서는 단순히 두 쿼리 메서드의 동작을 비교하였지만, 해당 주제와 연관하여 JPQL에서 LIMIT 사용 불가로 인한 우회 쿼리 생성, QueryDSL내 exists 키워드 사용 불가로 인한 selectOne(), fetchFirst() 사용 등의 추가적인 문제들이 남아있다. 해당 내용들도 차후 정리를 통하여 포스팅할 계획이다.