
UUID vs ULID, 인덱스로 사용하는 값에 따른 성능 비교
DESCRIPTION
최근 이메일 발송 기능의 실행을 보장하기 위하여 Transactional Outbox Pattern을 적용하기 위해, 프로젝트 일부에 Event 기반 구조를 도입하게 되었다. 이벤트를 아웃박스로 변환하여 저장할 때, 이벤트를 식별하기 위한 식별자가 필요하였다. Spring Event를 통한 이벤트, 아웃박스 제어를 위해 식별자를 애플리케이션 레벨에서 생성하고 저장하며 Non-Sequential 식별자를 사용하게 되었다. 이 과정에서 UUID보다는 ULID로 값을 저장하였을 때 성능적으로 발생할 수 있는 이점에 대해 알아본 경험을 공유하고자 한다.
서론
최근 ‘여행 기록 관리 플랫폼’ 프로젝트를 진행하며 이메일 발송 보장을 위하여 Transactional Outbox Pattern을 적용하기로 하였다. 이를 위하여 이벤트를 발송하는 일부 로직에 Spring Event 기반 구조를 도입하게 되었다.
이벤트를 아웃박스로 변환하여 저장할 때, 이벤트를 식별하기 위한 식별자가 필요하다.
이벤트를 식별하는 것 뿐만 아니라 처리된 이벤트에 대한 로그를 기록, 카프카로 이벤트 메시지 발행 시 처리 등을 위하여 이벤트를 구분하기 위한 식별자가 필요하다.
이벤트 기반 아키텍처(EDA)는 기본적으로 도메인 별로 서비스와 최적화된 데이터베이스를 별도로 가진다. 이러한 분산 환경에서 Auto-Increment 식별자는 데이터를 고유하게 식별하는데 어려움이 존재한다. 따라서, 순차적 PK(Sequential PK)가 아닌 비순차적 PK(Non-Sequential PK)를 사용하게 된다.
해당 프로젝트는 ‘모놀리식 단일 모듈’ 프로젝트이지만 차후 확장성을 고려하고, 애플리케이션 단에서 이벤트 아웃박스를 식별할 수 있는 eventId 컬럼 값을 생성하기로 설계하였기에 Non-Sequential PK를 사용하기로 하였다.
정확하게는 Non-Sequential한 값을 PK(id)로 사용하는 것은 아니다.
아웃박스의 PK는 Auto-Increment가 가능한 값을 사용하고, 아웃박스 별로 식별 가능한 별도의 컬럼인eventId를 두어 사용한다.
해당 방식을 사용한 이유는 포스팅 후반부에 설명한다.
eventId를 애플리케이션 레벨에서 생성하기로 한 이유 등은 향후 Transactional Outbox Pattern에 관한 포스팅에서 자세하게 다룰 예정이다.
이번 포스팅에서 중점적으로 다룰 주제는 Non-Sequential PK로 사용되는 값인 UUID와 ULID의 차이와 레코드 삽입, 조회 시 발생하는 성능 비교이다.
프로젝트에서는 ‘비밀번호 초기화 요청’과 ‘이메일 인증 코드 요청’ 기능 수행 후 이벤트를 발행하여 메일 발송이 이루어지도록 설계하였다.
이는 지속적으로 발생하는 이벤트가 아닌 일회성 이벤트이기 때문에, 아웃박스에 저장되는 데이터의 양이 매우 많을 것이라고 보기는 어렵다. 다만 향후 MSA 및 EDA 전환 가능성을 고려하여, 대규모 프로젝트 환경을 가정하고 이벤트 및 아웃박스 구조를 고민하였다.
eventId 컬럼의 식별자로 처음에 고려한 것은 UUID였다.
그러나 UUID를 키로 사용할 경우 성능상 문제가 발생할 수 있다는 내용을 이전에 접한 기억이 있어, 이벤트가 대량으로 발행/저장되는 환경에서는 적절하지 않을 수 있다고 판단하였다. 이에 따라 UUID를 식별자로 사용할 때 발생할 수 있는 문제점에 대해 보다 자세히 조사하였다.
키의 특성이 데이터베이스 성능에 영향을 미칠 수 있는 요소
우선, UUID나 ULID 등에 대해 알아보기 전에 키의 특성이 데이터베이스 성능에 영향을 미칠 수 있는 요소가 무엇이 있는지 정리해보고자 한다.
- 키의 크기 (Size of Key)
- 키의 순차성 (Sequentiality of Key)
이번 테스트를 통해 위 2가지의 요소가 향후 UUID와 ULID의 성능 차이를 일으킨다는 것을 알게되었다.
정확하게는 키의 크기는 작을수록, 키는 순차적일 수록 좋다고 할 수 있다. 자세하게는 위 2가지 요소를 기반으로 하여 아래의 특징들에서 성능 차이가 발생하게 된다.
- 키도 곧 특정 레코드의 데이터이다.
- 인덱스는 B+ Tree 구조를 가지며, 레코드 삽입 시 재배치가 이루어진다.
- 페이지에 행(row)가 거의 다 찰 경우 페이지 분할(Page Split)을 통하여 추가적인 페이지를 확보한다.
- RandomID를 사용할 경우 Cache Miss가 발생할 확률이 높다.
1. 키도 곧 특정 레코드의 데이터이다.
말 그대로, 키도 곧 데이터이다.
키의 길이가 길수록 한 행(row)의 크기가 커지기 때문에 페이지 내 들어갈 수 있는 데이터(row)의 갯수가 줄어든다.
2. 인덱스는 B+ Tree 구조를 가지며, 레코드 삽입 시 재배치가 이루어진다.
인덱스는 데이터를 빠르게 찾기 위해 (키, 값) 쌍으로 구성된 B+ Tree 자료구조이다.
MySQL에서는 주 인덱스와 보조 인덱스가 존재한다.
주 인덱스는 클러스터링 인덱스로 키를 PK, 값을 레코드 전체로 가지는 인덱스이다. 즉, 테이블에 데이터 삽입 시 PK를 통해 값이 삽입된다.
보조 인덱스는 논-클러스터링 인덱스로 키를 특정 컬럼, 값을 PK로 가지는 인덱스이다. 즉, PK를 제외하고 다른 컬럼들을 통해 사용자가 직접 지정하여 생성된 인덱스를 의미한다.
인덱스는 B+ Tree의 키를 기준으로 정렬이 되어있으며, 리프노드들은 페이지이다. 주 인덱스는 각 페이지마다 레코드들이 저장되어있고, 보조 인덱스는 (키, PK) 쌍이 저장되어 있다.
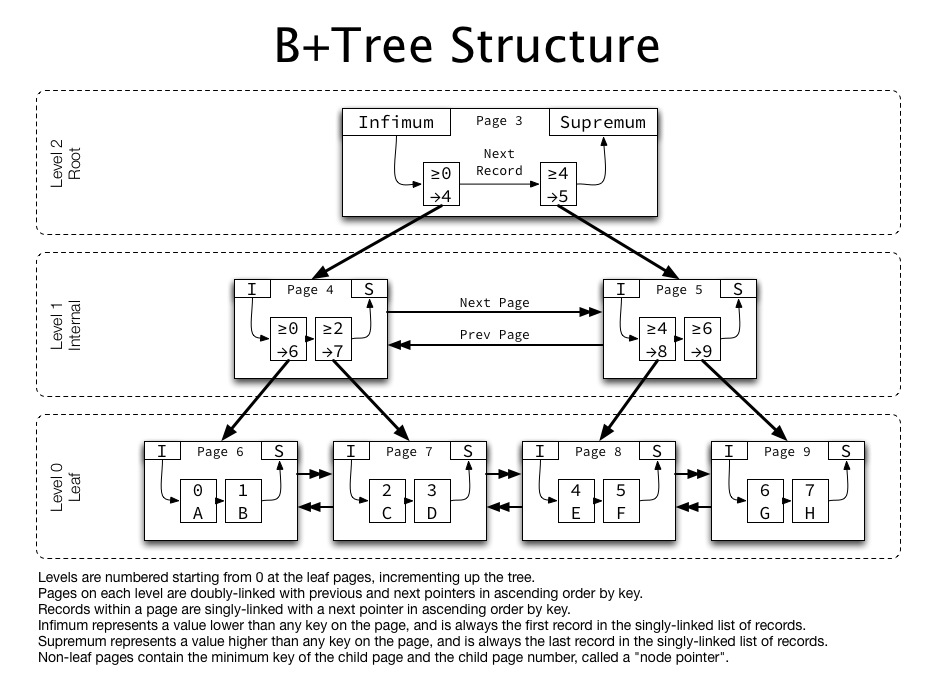
위 그림은 MySQL이 기본적으로 사용하는 데이터베이스 엔진인 InnoDB에서 사용하는 B+ Tree 구조를 나타낸 그림이다.
리프노드는 실제 레코드가 담긴 페이지로 구성되어 있으며, 키를 기준으로 정렬되어 있는 것을 알 수 있다.
즉, 새로운 데이터가 삽입이 되며 정렬된 키 순서를 유지하며 B+ Tree 구조를 만족하기 위해 재배치가 이루어진다.
각 페이지가 꽉 찰 때까지는 해당 페이지 내에서 레코드의 정렬 순서를 변경하는 등의 방법으로 재배치를 수행하게 된다.
그러나, 페이지가 꽉찬 상태에서 레코드가 삽입된 경우에는 페이지 분할이 필요하다.
3. 페이지에 행(row)가 거의 다 찰 경우 페이지 분할(Page Split)을 통하여 추가적인 페이지를 확보한다.
해당 특징이 레코드 삽입 시 UUID와 ULID의 성능 차이를 불러일으키는 결정적 요인이다.
페이지가 가득찬 상태에서 추가 레코드가 삽입될 경우, 키의 순차 여부에 따라 페이지가 분할되는 방식에서 차이가 발생한다.
MySQL 공식 문서에 따르면 InnoDB의 인덱스는 추가 레코드가 삽입 되었을 때, 페이지 내 1/16 정도의 공간은 남겨둔다고 한다.
따라서 결과적으로 생성되는 인덱스 페이지는 순차 삽입의 경우에는 대부분 15/16 만큼 채워져있으며, 랜덤 삽입의 경우에는 1/2(=50%)에서 15/16까지 채워져있다고 한다. 여기서 순차 삽입과 랜덤 삽입 시 결과 인덱스 페이지가 채워진 비율이 다르다는 점이 두 방식의 페이지 분할(Page Split) 기법도 다르다는 것을 나타낸다.
페이지 분할 방식의 차이는 데이터베이스 오픈소스 소프트웨어 프로젝트 개발 회사인 Percona의 기술 블로그 포스트 “The Impacts of Fragmentation in MySQL”에서 확인할 수 있었다.
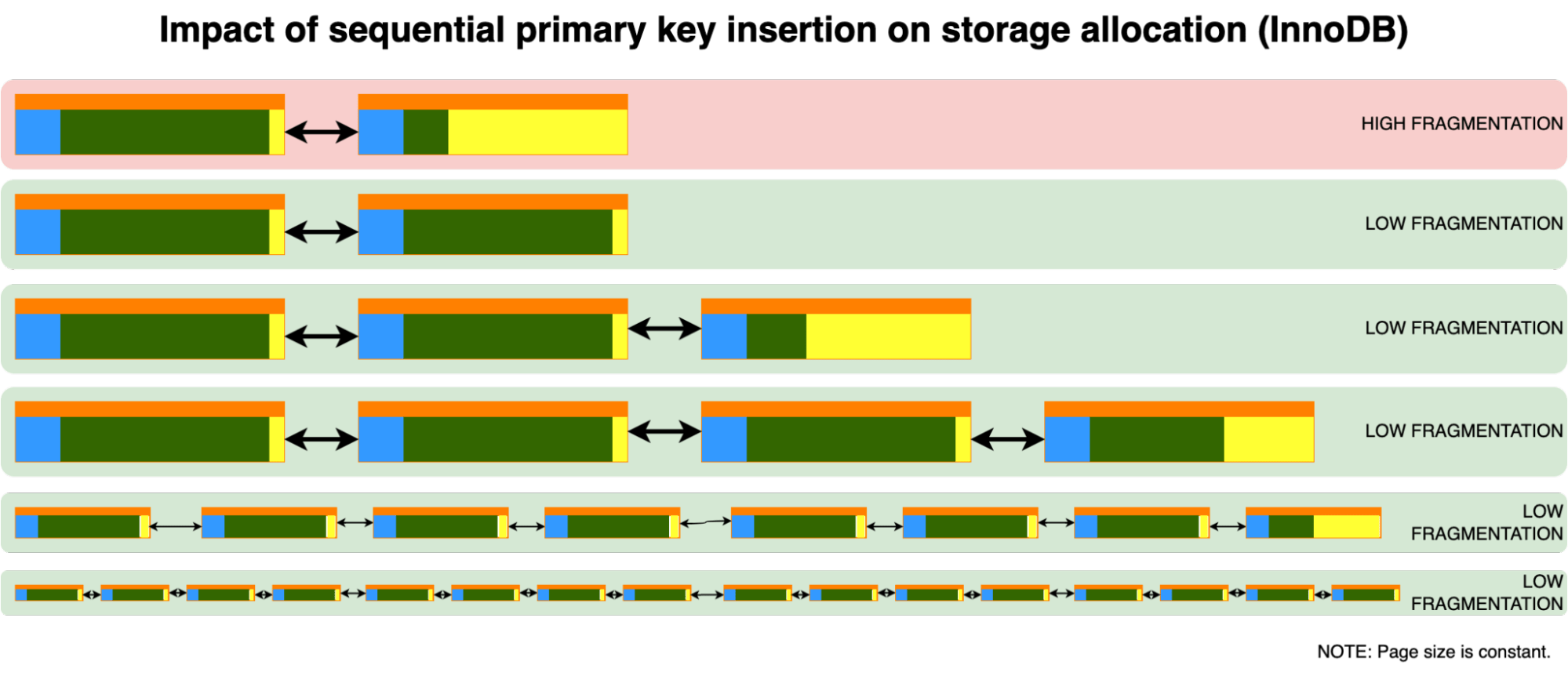
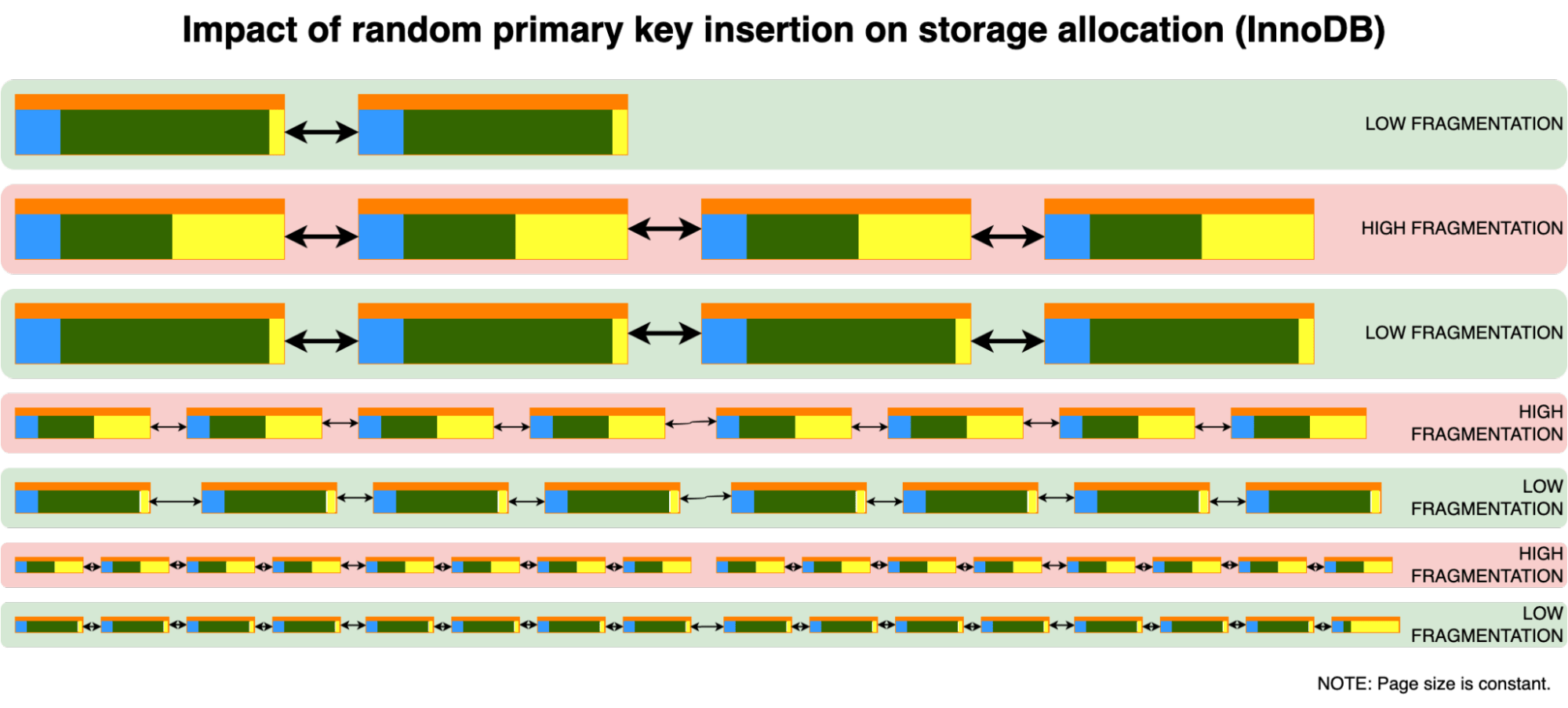
해당 포스트에 따르면, InnoDB 엔진은 레코드가 삽입되었을 때 매우 영리한 방법으로 동작한다고 한다. 새로운 페이지(empty page)를 만들지, 페이지를 분할(page split)할지는 삽입되는 레코드에 따라 다르다고 한다.
순차 삽입의 경우에는 기존의 페이지를 분할하는 것이 아닌 새로운 페이지를 만들어 해당 페이지에 레코드를 삽입한다고 한다. Auto Increment 키를 사용하는 것이 성능상 큰 이점을 가지고 온다는 것이다.
그러나, 랜덤 삽입의 경우에는 향후 삽입될 레코드가 어느 위치에 삽입이 될 지 모르기 때문에 기존 페이지도 충분한 여유 공간을 확보해야한다. 따라서, 페이지 분할 기법을 이용하여 기존 페이지의 레코드의 절반을 새로 생성된 페이지에 옮긴다. 따라서, 각 새로 생성되는 페이지에 절반의 레코드를 옮기기 때문에 결과적으로 1/2(=50%) ~ 15/16까지 인덱스 페이지 내 레코드가 채워지게 되는 것이다.
페이지 분할(Page Split) 자체도 되게 비용이 큰 무거운 연산이며, 레코드의 크기가 클 수록 페이지는 더욱 빨리 채워질 것이기에 페이지 분할도 많이 발생할 것이다.
4. RandomID를 사용할 경우 Cache Miss가 발생할 확률이 높다.
MySQL은 레코드 조회 시 해당 레코드만 메모리로 로드하는 것이 아니라, 해당 레코드가 포함된 페이지를 읽어와 InnoDB Buffer Pool에 적재한다.
즉, 페이지에 담긴 레코드의 수가 많을 수록 더 많은 레코드들이 메모리의 Buffer Pool에 올라올 수 있게 되는 것이다.
RandomID의 경우에는 비슷한 시간대에 생성된 레코드이더라도 위치한 페이지가 다를 가능성이 높기 때문에 Buffer Pool에 해당 페이지가 존재하지 않는 Cache Miss가 발생할 확률이 높다. 즉, 이후 레코드를 또 조회하기 위해서는 해당 레코드를 포함한 페이지 로드 Disk I/O 작업이 빈번하게 이루어지게 되는 것이다.
키의 순차성뿐만이 아니라 키의 크기가 클수록 Cache Miss의 발생 확률이 증가한다. 키도 레코드의 데이터 중 하나이기 때문에 키의 크기가 클수록 레코드의 크기도 증가하게 된다. 레코드의 크기가 증가하면 페이지 내 적재될 수 있는 레코드의 수는 줄어들게 된다. 따라서, Cache Miss 발생 확률이 증가하게 되는 것이다.
UUID vs ULID
키의 크기와 키의 순차성에 따라 데이터베이스 성능에 영향을 미치게 된다. 그렇다면 UUID와 ULID는 어떠한 차이가 있는지 알아보자.
UUID
UUID(Universally Unique Identifier)는 128-bit의 고유 식별자이다. 중앙 시스템에서 ID를 발급하는 형식이 아니기에 빠르고 간단하게 ID를 생성할 수 있는 방법이다. 필자가 애플리케이션 레벨에서 이벤트를 구분하기 위한 eventId 값을 만들기 위해 가장 먼저 생각난 방법이 UUID이다.
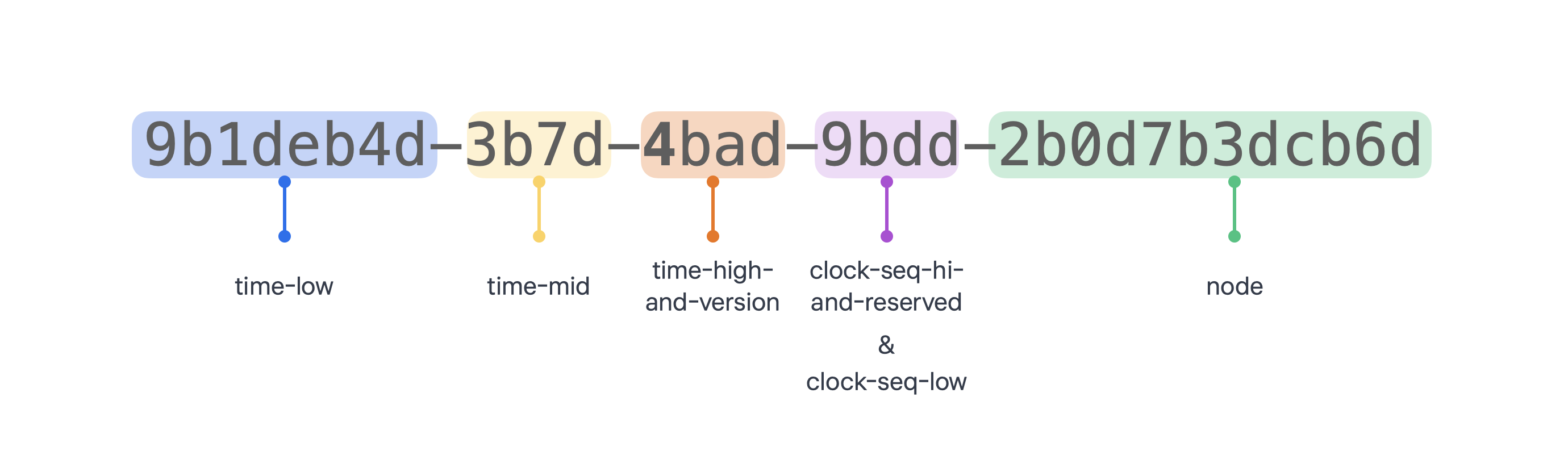
UUID는 8-4-4-4-12 자리로 구성되어있으며 16진수로 표현한다. 특히, 3번째 필드의 첫번째 자리는 버전 정보를 나타낸다. 하이픈(-)까지 포함하면 총 36글자이다.
Java에서는 java.util 패키지에서 UUID 클래스를 제공한다. UUID는 다양한 버전이 있으면 해당 클래스는 UUID v4 기준이다.
- UUID v1: 시간 + MAC 주소
- UUID v2: 시간 + POSIX
- UUID v3: 고정된 이름 + Namespace ⇒ MD5 해시
- UUID v4: 무작위 랜덤값(버전 정보 제외)
- UUID v5: 고정된 이름 + Namespace ⇒ SHA-1 해시
- UUID v6: 시간(정렬하기 좋게 재배치) + MAC
- UUID v7: Unix 시간 + 랜덤값
Java에서 기본적으로 제공하는 UUID의 경우에는 완전 무작위값이므로 충돌 가능성이 매우 낮지만, 이를 키로 사용할 경우에 앞서 보았던 데이터베이스 성능 문제가 발생할 수 있다. 따라서, 데이터베이스의 키 값으로 UUID 사용을 고려한다면 UUID v4 보다는 타임스탬프(시간) 값을 기반으로 하는 다른 버전의 UUID를 사용하는 것이 도움이 될 것이다.
ULID
ULID(Universally Unique Lexicographically Sortable Identifier)는 이름 그대로 사전적으로 정렬 가능한 범용 고유 식별자를 의미한다. 여기서, 사전적으로 정렬 가능하다라는 뜻은 ASCII 코드를 기준으로 문자의 크기를 비교하여 정렬하는 것을 나타낸다.
01EX8Y7M8M DVX3M3EQG69EEMJW
01EX8Y7M8M DVX3M3EQG69EEMJX
01EX8Y7M8M DVX3M3EQG69EEMJY
01EX8Y7M8M DVX3M3EQG69EEMJZ
01EX8Y7M8M DVX3M3EQG69EEMK0
01EX8Y7M8M DVX3M3EQG69EEMK1
01EX8Y7M8M DVX3M3EQG69EEMK2
01EX8Y7M8M DVX3M3EQG69EEMK3
01EX8Y7M8N 1G30CYF2PJR23J2J < millisecond changed
01EX8Y7M8N 1G30CYF2PJR23J2K
01EX8Y7M8N 1G30CYF2PJR23J2M
01EX8Y7M8N 1G30CYF2PJR23J2N
01EX8Y7M8N 1G30CYF2PJR23J2P
01EX8Y7M8N 1G30CYF2PJR23J2Q
01EX8Y7M8N 1G30CYF2PJR23J2R
01EX8Y7M8N 1G30CYF2PJR23J2S
^ ^
|--------|----------------|
time randomness
(48) (80)
ULID는 Timestamp 48-bit + Randomess 80-bit로 구성되어 총 128-bit로 구성된 고유 식별자이다.
UUID와 동일하게 128-bit이지만, ULID는 32진수를 쓰기 때문에 총 26글자로 구성된다.
ULID의 Timestamp는 millisecond까지 감지 하기 때문에 1 ms가 지나면 앞 48-bit의 최하위 비트를 1 증가시키는 형식이다. 또한, 동일한 시간대이더라도 하위 80-bit가 랜덤으로 주어진다. 즉, 동일한 시점이더라도 2^80 가지 경우의 수가 존재한다.
하지만, 난수라고해서 무조건 신뢰할 수 없기 때문에 동일한 시점에 생성된 ULID는 초기 랜덤 80-bit를 기준으로 1씩 증가하며 생성되기 때문에 충돌 가능성이 거의 없도록 한다.
UUID와 ULID의 차이
이 시점에서 앞서 보았던 데이터베이스의 성능 차이를 발생시키는 요소에 기반하여 UUID(v4 기준)와 ULID를 비교하면 다음과 같다.
- UUID는 36글자, ULID는 26글자로 구성된다.
- UUID는 완전한 무작위 값(=비순차적), ULID는 타임스탬프 기반 값(=순차적)으로 구성된다.
이러한 사실만 놓고 보더라도 InnoDB 엔진을 사용하는 MySQL에 레코드의 식별자로 UUID보다 ULID를 사용할 경우에 성능적으로 이점이 있다는 것을 예측할 수 있다.
그러나, 학부생 수준에서 진행하는 프로젝트에서는 대규모 데이터가 생성되고 저장되는 일이 잘 없기 때문에, 구체적인 수치를 눈으로 확인하고 비교하기 위해 Spring과 MySQL을 통한 실험을 진행하였다.
UUID vs ULID 성능 비교 테스트
해당 테스트는 식별자로 사용하는 값에 따른 인덱스 재배치 및 페이지 분할 발생 빈도수 차이 등을 확인하는 것을 목적으로 하고 있기에 레코드 삽입에 중점이 맞추어져있다.
테스트 환경은 다음과 같다.
- Framework: SpringBoot 4.0.1
- Database: MySQL 9.2.0
- CPU: Apple M1
- RAM: 16GB
- Library: ULID Creator 5.2.3
각 테이블은 UUID와 ULID를 PK로 가지며, 각 식별자의 정확한 길이에 따른 비교를 위해 varchar 타입으로 구성하였다.
mysql> describe uuid_table;
+-------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+-------+
| id | varchar(36) | NO | PRI | NULL | |
| data | varchar(255) | YES | | NULL | |
+-------+--------------+------+-----+---------+-------+
mysql> describe ulid_table;
+-------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+-------+
| id | varchar(26) | NO | PRI | NULL | |
| data | varchar(255) | YES | | NULL | |
+-------+--------------+------+-----+---------+-------+
각 테이블명은 uuid_table과 ulid_table이다.
테이블 생성 후 초기 크기는 다음과 같다.
mysql> SELECT TABLE_NAME, DATA_LENGTH AS 'Pure_Data_Size_Bytes', ROUND(DATA_LENGTH / 1024, 2) AS 'Pure_Data_Size_KB', TABLE_ROWS AS 'Total_Rows'
FROM information_schema.TABLES
WHERE TABLE_NAME LIKE '%uuid_table%' OR TABLE_NAME LIKE '%ulid_table%';
+------------+----------------------+-------------------+------------+
| TABLE_NAME | Pure_Data_Size_Bytes | Pure_Data_Size_KB | Total_Rows |
+------------+----------------------+-------------------+------------+
| ulid_table | 16384 | 16 | 0 |
| uuid_table | 16384 | 16 | 0 |
+------------+----------------------+-------------------+------------+
각 테스트는 SpringBoot의 테스트 코드를 통해 이루어졌으며, JPA 사용으로 불필요한 오버헤드 방지를 위해 jdbcTemplate 기반으로 코드를 작성하였다.
@SpringBootTest
public class IndexComparisonTest {
private final JdbcTemplate jdbcTemplate;
private final int RECORD_SIZE = 100_000;
@Autowired
public IndexComparisonTest(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Test
@DisplayName("UUID를 PK로 하는 테이블 삽입")
public void insertUUID() {
String sql = "INSERT INTO uuid_table (id, data) VALUES (?, 'data')";
StopWatch st = new StopWatch();
st.start("UUID");
for (int i = 0; i < RECORD_SIZE; i++) {
jdbcTemplate.update(sql, UUID.randomUUID().toString());
}
st.stop();
System.out.println(st.prettyPrint());
}
@Test
@DisplayName("ULID를 PK로 하는 테이블 삽입")
public void insertULID() {
String sql = "INSERT INTO ulid_table (id, data) VALUES (?, 'data')";
StopWatch st = new StopWatch();
st.start("ULID");
for (int i = 0; i < RECORD_SIZE; i++) {
jdbcTemplate.update(sql, UlidCreator.getUlid().toString());
}
st.stop();
System.out.println(st.prettyPrint());
}
}
우선, 삽입할 레코드의 크기를 100,000개로 설정한 뒤 삽입 테스트를 진행하였다.
100,000개 레코드 삽입
(1) 삽입 소요 시간
| UUID | ULID |
| 81.16s | 79.89s |
삽입 소요 시간에서는 근소한 차이를 보이지만 UUID가 조금 더 오래걸리는 것을 알 수 있다. 페이지 분할이나 인덱스 재배치 등으로 인해 발생하는 오버헤드로 인한 차이일 것이다. 이는 데이터의 수가 많을수록 더욱 극명하게 나타날 것이다.
(2) 페이지 분할 횟수
# uuid_table에 레코드 삽입 후
mysql> select name, count from INFORMATION_SCHEMA.INNODB_METRICS where name like 'index_page%';
+-----------------------------+-------+
| name | count |
+-----------------------------+-------+
| index_page_splits | 564 |
| index_page_merge_attempts | 0 |
| index_page_merge_successful | 0 |
| index_page_reorg_attempts | 0 |
| index_page_reorg_successful | 0 |
| index_page_discards | 0 |
+-----------------------------+-------+
# ulid_talbe에 레코드 삽입 후
mysql> select name, count from INFORMATION_SCHEMA.INNODB_METRICS where name like 'index_page%';
+-----------------------------+-------+
| name | count |
+-----------------------------+-------+
| index_page_splits | 341 |
| index_page_merge_attempts | 0 |
| index_page_merge_successful | 0 |
| index_page_reorg_attempts | 0 |
| index_page_reorg_successful | 0 |
| index_page_discards | 0 |
+-----------------------------+-------+
| UUID | ULID |
| 564 | 341 |
페이지 분할 횟수에서는 100,000개의 레코드임에도 차이가 뚜렷하게 나타났다.
UUID가 ULID보다 페이지 분할 횟수가 많은 이유는 키의 길이가 더 길고, 랜덤(비순차) 삽입이 이루어지기 때문에 기존 페이지와 새로 생성되는 페이지에 1/2씩 레코드를 나눠가지게 분할이 되기 때문임을 알 수 있다.
(3) 인덱스로 인해 할당된 페이지 수
mysql> SELECT
database_name,
table_name,
index_name,
stat_value AS 'Total_Pages',
stat_description AS 'Description'
FROM mysql.innodb_index_stats
WHERE (table_name LIKE '%uuid_table%' OR table_name LIKE '%ulid_table%')
AND stat_name = 'size';
+---------------+------------+------------+-------------+------------------------------+
| database_name | table_name | index_name | Total_Pages | Description |
+---------------+------------+------------+-------------+------------------------------+
| index_test | ulid_table | PRIMARY | 353 | Number of pages in the index |
| index_test | uuid_table | PRIMARY | 675 | Number of pages in the index |
+---------------+------------+------------+-------------+------------------------------+
주 키로 인해 생성된 클러스터링 인덱스에 할당된 총 페이지 수는 ulid_table은 353, uuid_table은 675 페이지가 생성된 것을 알 수 있다.
100,000개의 레코드 삽입 시 생성된 페이지 수는 약 1.9배 차이라는 것을 알 수 있다. 이또한, 레코드가 더욱 많아질수록 차이가 클 것이다.
(4) 테이블 크기
mysql> SELECT TABLE_NAME, DATA_LENGTH AS 'Pure_Data_Size_Bytes', ROUND(DATA_LENGTH / 1024 / 1024, 2) AS 'Pure_Data_Size_MiB'
FROM information_schema.TABLES
WHERE TABLE_NAME LIKE '%uuid_table%' OR TABLE_NAME LIKE '%ulid_table%';
+------------+----------------------+-------------------+
| TABLE_NAME | Pure_Data_Size_Bytes | Pure_Data_Size_MiB |
+------------+----------------------+-------------------+
| ulid_table | 5783552 | 5.52 |
| uuid_table | 11059200 | 10.55 |
+------------+----------------------+-------------------+
테이블 자체 크기는 ulid_table는 5.78MB, uuid_table은 11MB이다.
이또한 약 2배 정도의 차이를 보이고 있다.
(5) 페이지 당 평균 레코드 수 및 Fill Factor
mysql> SELECT
SUBSTRING_INDEX(TABLE_NAME, '.', -1) AS 'Pure_Table_Name',
COUNT(*) AS 'Pages_In_Buffer',
ROUND(AVG(DATA_SIZE) / 16384 * 100, 1) AS 'Real_Fill_Factor_Percent',
ROUND(AVG(NUMBER_RECORDS), 1) AS 'Avg_Records_Per_Page'
FROM information_schema.INNODB_BUFFER_PAGE
WHERE TABLE_NAME LIKE '%uuid_table%' OR TABLE_NAME LIKE '%ulid_table%'
AND INDEX_NAME = 'PRIMARY'
GROUP BY TABLE_NAME;
+-----------------+-----------------+--------------------------+----------------------+
| Pure_Table_Name | Pages_In_Buffer | Real_Fill_Factor_Percent | Avg_Records_Per_Page |
+-----------------+-----------------+--------------------------+----------------------+
| `ulid_table` | 341 | 91.5 | 294.3 |
| `uuid_table` | 580 | 64.5 | 173.4 |
+-----------------+-----------------+--------------------------+----------------------+
페이지 당 할당된 레코드 수는 Buffer Pool에 올라온 페이지를 기준으로 확인한다.
MySQL의 information_schema.INNODB_BUFFER_PAGE에서는 버퍼풀에 올라온 페이지에 대한 다양한 정보를 제공한다.
이번 지표(Metric)에서 주요하게 확인할 것은 Fill Factor와 페이지 당 평균 레코드 수이다.
Fill Factor의 경우에는 ulid_table은 평균적으로 91.5%의 비율, uuid_table은 평균적으로 64.5%의 비율로 레코드가 채워져있다. MySQL InnoDB 엔진 설명과 유사한 결과 양상을 보이고 있다.
페이지 당 평균 레코드 수는 ulid_table은 평균적으로 294.3개, uuid_table은 평균적으로 173.4개의 레코드가 채워져있다. UUID가 키의 길이가 더욱 길기도 하며, 페이지 분할 시 Fill Factor의 차이로 인하여 페이지 당 평균 레코드수가 낮은 것을 확인할 수 있다.
페이지 당 평균 레코드 수가 낮으므로 UUID 사용 시 Cache Miss 확률이 더 높을 것이다.
(6) I/O Write Request
mysql> SELECT
table_name,
rows_fetched,
rows_inserted,
io_read_requests,
io_write_requests
FROM sys.schema_table_statistics
WHERE table_name LIKE '%uuid_table%' OR table_name LIKE '%ulid_table%';
+------------+--------------+---------------+------------------+-------------------+
| table_name | rows_fetched | rows_inserted | io_read_requests | io_write_requests |
+------------+--------------+---------------+------------------+-------------------+
| ulid_table | 0 | 100000 | 0 | 420 |
| uuid_table | 0 | 100000 | 0 | 2681 |
+------------+--------------+---------------+------------------+-------------------+
다음은 테이블에 대한 레코드(row)를 조회, 삽입 횟수와 Read/Write Disk I/O를 나타낸 지표이다.
두 테이블 모두 100,000개의 레코드가 삽입되었지만 io_write_requests의 경우에는 약 6배 이상의 극명한 차이를 보인다.
UUID의 경우 앞서 말한 페이지 분할의 특성으로 인하여 기존 페이지 수정 + 새로 생긴 페이지 기록 + 인덱스 트리 구조 수정 등 I/O 작업이 다수 발생하며, 더욱 빈번하게 발생하므로 이러한 차이가 발생한다는 것을 알 수 있다.
300,000개 레코드 삽입
테스트 코드에서 RECORD_SIZE = 300_000으로 수정하여 300,000개 레코드 삽입 시에 발생하는 성능 차이를 확인하였다. 이때, 기존 테이블은 삭제 후 새로 생성하여 테스트를 진행하였다.
(1) 삽입 소요 시간
| UUID | ULID |
| 350.15s | 328.62s |
100,000개의 레코드 삽입 시에는 약 2초 정도의 차이가 있었지만, 300,000개의 레코드 삽입 시에는 UUID가 ULID보다 약 22초 이상 더 소요된 것을 확인할 수 있다.
(2) 페이지 분할 횟수
mysql> SELECT name, count FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE name = 'index_page_splits';
+-------------------+-------+
| name | count |
+-------------------+-------+
| index_page_splits | 1838 |
+-------------------+-------+
mysql> SELECT name, count FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE name = 'index_page_splits';
+-------------------+-------+
| name | count |
+-------------------+-------+
| index_page_splits | 1019 |
+-------------------+-------+
100,000개의 레코드 삽입 시에는 페이지 분할 횟수 차이가 223인 반면, 300,000개 레코드 삽입 시에는 819회 차이가 나는 것을 확인할 수 있다. 이는 약 1.8배 정도의 차이이다.
(3) 인덱스로 인해 할당된 페이지 수
mysql> SELECT
database_name,
table_name,
index_name,
stat_value AS 'Total_Pages',
stat_description AS 'Description'
FROM mysql.innodb_index_stats
WHERE (table_name LIKE '%uuid_table%' OR table_name LIKE '%ulid_table%')
AND stat_name = 'size';
+---------------+------------+------------+-------------+------------------------------+
| database_name | table_name | index_name | Total_Pages | Description |
+---------------+------------+------------+-------------+------------------------------+
| index_test | ulid_table | PRIMARY | 996 | Number of pages in the index |
| index_test | uuid_table | PRIMARY | 1897 | Number of pages in the index |
+---------------+------------+------------+-------------+------------------------------+
할당된 페이지 수 또한 UUID가 ULID보다 901개의 페이지가 더 많이 생성된 것을 확인할 수 있다.
(4) 테이블 크기
mysql> SELECT TABLE_NAME, DATA_LENGTH AS 'Pure_Data_Size_Bytes', ROUND(DATA_LENGTH / 1024 / 1024, 2) AS 'Pure_Data_Size_MiB' FROM information_schema.TABLES WHERE TABLE_NAME LIKE '%uuid_table%' OR TABLE_NAME LIKE '%ulid_table%';
+------------+----------------------+--------------------+
| TABLE_NAME | Pure_Data_Size_Bytes | Pure_Data_Size_MiB |
+------------+----------------------+--------------------+
| ulid_table | 17367040 | 16.56 |
| uuid_table | 33177600 | 31.64 |
+------------+----------------------+--------------------+
테이블 크기의 경우에도 약 2배 정도의 차이를 보이고 있으며 단순 텍스트 데이터만 가진 레코드이더라도 극명한 차이를 보이고 있다는 것을 알 수 있다.
(5) 페이지 당 평균 레코드 수 및 Fill Factor
mysql> SELECT
SUBSTRING_INDEX(TABLE_NAME, '.', -1) AS 'Pure_Table_Name',
COUNT(*) AS 'Pages_In_Buffer',
ROUND(AVG(DATA_SIZE) / 16384 * 100, 1) AS 'Real_Fill_Factor_Percent',
ROUND(AVG(NUMBER_RECORDS), 1) AS 'Avg_Records_Per_Page'
FROM information_schema.INNODB_BUFFER_PAGE
WHERE TABLE_NAME LIKE '%uuid_table%' OR TABLE_NAME LIKE '%ulid_table%'
AND INDEX_NAME = 'PRIMARY'
GROUP BY TABLE_NAME;
+-----------------+-----------------+--------------------------+----------------------+
| Pure_Table_Name | Pages_In_Buffer | Real_Fill_Factor_Percent | Avg_Records_Per_Page |
+-----------------+-----------------+--------------------------+----------------------+
| `uuid_table` | 1755 | 63.9 | 171.9 |
| `ulid_table` | 1022 | 91.6 | 294.5 |
+-----------------+-----------------+--------------------------+----------------------+
Fill Factor의 경우에는 기존과 유사하게 ulid_table은 평균적으로 91.6%의 비율, uuid_table은 평균적으로 63.9%의 비율로 레코드가 채워진다는 것을 알 수 있다.
페이지당 평균 레코드 수 또한 기존과 유사하게 ulid_table은 171.9개, uuid_table은 294.5개를 가진다.
따라서, 삽입되는 레코드의 수가 증가하더라도 이러한 양상은 유지된다는 것을 알 수 있다.
(6) I/O Write Request
SELECT
table_name,
rows_fetched,
rows_inserted,
io_read_requests,
io_write_requests
FROM sys.schema_table_statistics
WHERE table_name LIKE '%uuid_table%' OR table_name LIKE '%ulid_table%';
+------------+--------------+---------------+------------------+-------------------+
| table_name | rows_fetched | rows_inserted | io_read_requests | io_write_requests |
+------------+--------------+---------------+------------------+-------------------+
| uuid_table | 0 | 300000 | 0 | 106372 |
| ulid_table | 0 | 300000 | 0 | 1316 |
+------------+--------------+---------------+------------------+-------------------+
I/O Write Request의 경우 UUID는 106,372회, ULID는 1,316회 발생하였으며 이는 약 80배의 차이이다.
삽입되는 레코드 양이 커질수록 페이지 분할 및 인덱스 재배치 횟수도 커지기 때문에 극명한 차이를 보이게 된다.
위의 테스트 과정을 통해 다음과 같은 사실들을 도출해낼 수 있었다.
- 키의 크기가 성능에 영향을 미친다.
- 키가 클수록, 페이지 당 삽입 가능 레코드 수가 줄어들게 되어 성능이 저하한다.
- 키의 순차성이 성능에 영향을 미친다.
- 순차키의 경우에는 페이지 분할 시, 새로운 페이지에 추가된 레코드를 삽입하게 된다.
- 비순차키의 경우에는 페이지 분할 시, 새로운 페이지에 기존 페이지의 레코드 절반을 옮긴다.
- 따라서, 비순차키 사용 시 페이지 분할과 인덱스 재배치가 빈번하게 일어나게 된다.
- UUID는 키의 크기가 상대적으로 크고, 랜덤(비순차)한 식별자이다.
- ULID는 키의 크기가 상대적으로 작고, 순차적인 식별자이다.
- 레코드의 양이 많을수록 데이터베이스 성능 차이가 극명하게 발생한다.
PK가 아닌 보조 인덱스로 사용할 경우
앞서 서론 부분에 이벤트 아웃박스의 eventId 컬럼을 PK가 아닌 일반 컬럼으로 두고, 보조 인덱스로 사용한다고 하였다.
보조인덱스로 사용한다면 레코드의 크기가 또 증가할텐데 이렇게 선택한 이유는 보조 인덱스는 논-클러스터링 인덱스이기 때문이다.
실제 운영환경에서는 테이블의 크기가 큰 경우가 많다. 필자가 해당 기능을 위해 저장하는 이벤트 아웃박스도 createdAt, last_retried_at, payload 등 다양한 컬럼이 존재하며, payload의 경우에는 여러 이벤트마다 크기가 다르기 때문에 적당히 큰 크기로 설정해놓은 상태이다.
이러한 상황에서 PK를 Non-Sequential PK로 사용할 경우, 인덱스 재배치가 이루어지는 과정에서 레코드 전체가 재배치가 발생하여 큰 오버헤드가 발생할 것이다.
따라서, 레코드의 크기가 큰 경우에는 PK는 Auto Increment, 보조 인덱스는 키의 크기가 작고, Sequential한 값을 사용하는 것이 효율적일 것 이다.
만약, PK는 Auto Increment한 값을 사용하고 보조 인덱스로 UUID와 ULID를 사용하는 테이블에 100,000개 레코드를 삽입한다면 결과는 다음과 같다.
// PK는 Auto Increment + 보조 인덱스는 ULID
+-------------------+-------+
| name | count |
+-------------------+-------+
| index_page_splits | 1281 |
+-------------------+-------+
// PK는 Auto Increment + 보조 인덱스는 UUID
+-------------------+-------+
| name | count |
+-------------------+-------+
| index_page_splits | 1783 |
+-------------------+-------+
+---------------+----------------------+------------+-------------+------------------------------+
| database_name | table_name | index_name | Total_Pages | Description |
+---------------+----------------------+------------+-------------+------------------------------+
| index_test | ulid_secondary_table | PRIMARY | 995 | Number of pages in the index |
| index_test | ulid_secondary_table | idx_ulid | 289 | Number of pages in the index |
| index_test | uuid_secondary_table | PRIMARY | 1123 | Number of pages in the index |
| index_test | uuid_secondary_table | idx_uuid | 611 | Number of pages in the index |
+---------------+----------------------+------------+-------------+------------------------------+
mysql> SELECT TABLE_NAME, DATA_LENGTH AS 'Pure_Data_Size_Bytes', ROUND(DATA_LENGTH / 1024 / 1024, 2) AS 'Pure_Data_Size_MiB' FROM information_schema.TABLES WHERE TABLE_NAME LIKE '%uuid_secondary_table%' OR TABLE_NAME LIKE '%ulid_secondary_table%';
+----------------------+----------------------+--------------------+
| TABLE_NAME | Pure_Data_Size_Bytes | Pure_Data_Size_MiB |
+----------------------+----------------------+--------------------+
| ulid_secondary_table | 16302080 | 15.55 |
| uuid_secondary_table | 18399232 | 17.55 |
+----------------------+----------------------+--------------------+
+------------------------+------------+-----------------+--------------------------+----------------------+
| Pure_Table_Name | INDEX_NAME | Pages_In_Buffer | Real_Fill_Factor_Percent | Avg_Records_Per_Page |
+------------------------+------------+-----------------+--------------------------+----------------------+
| `ulid_secondary_table` | PRIMARY | 1035 | 91.5 | 97.6 |
| `ulid_secondary_table` | idx_ulid | 251 | 97.5 | 399.4 |
| `uuid_secondary_table` | PRIMARY | 1091 | 92.4 | 92.7 |
| `uuid_secondary_table` | idx_uuid | 506 | 60.6 | 198.6 |
+------------------------+------------+-----------------+--------------------------+----------------------+
위 결과에서 ULID를 보조 인덱스로 사용하는 경우, 주 인덱스와 보조 인덱스의 Fill Factor가 모두 90% 이상을 차지하고 있는 것을 알 수 있다.
그러나, 보조 인덱스 자체도 인덱스를 형성해야하며 해당 컬럼들이 레코드 내 데이터이기 때문에 테이블의 크기가 거치고, 인덱스 자체가 2개이니 페이지 분할 횟수도 Non-Sequential한 값을 PK로 사용했을 때보다 증가한 것을 알 수 있다.
따라서, ‘Auto Increment PK + 보조 인덱스는 UUID’ 조합은 테이블의 크기도 키우고, 페이지 분할 횟수와 인덱스 재배치 효율도 떨어지는 최악의 조합이라는 것을 알 수 있다.
그렇다면 “ULID를 보조 인덱스로 사용해도 어차피 페이지 분할 횟수나 테이블 크기가 커지는데 이것이 과연 좋은가?”라는 의문을 가질 수 있다.
그러나, 위 테스트는 레코드의 크기가 작은 경우이다. 레코드의 크기가 큰 상황을 가정하여 ULID를 PK로 사용하는 경우 vs ULID를 보조 인덱스로 사용하는 경우를 비교해보자.
mysql> describe heavy_ulid_pk;
+------------+---------------+------+-----+-------------------+-------------------+
| Field | Type | Null | Key | Default | Extra |
+------------+---------------+------+-----+-------------------+-------------------+
| id | varchar(26) | NO | PRI | NULL | |
| content | varchar(2000) | YES | | NULL | |
| created_at | timestamp | YES | | CURRENT_TIMESTAMP | DEFAULT_GENERATED |
+------------+---------------+------+-----+-------------------+-------------------+
mysql> describe heavy_ulid_sec;
+------------+---------------+------+-----+-------------------+-------------------+
| Field | Type | Null | Key | Default | Extra |
+------------+---------------+------+-----+-------------------+-------------------+
| id | bigint | NO | PRI | NULL | auto_increment |
| sub_id | varchar(26) | NO | MUL | NULL | |
| content | varchar(2000) | YES | | NULL | |
| created_at | timestamp | YES | | CURRENT_TIMESTAMP | DEFAULT_GENERATED |
+------------+---------------+------+-----+-------------------+-------------------+
레코드의 크기가 큰 2가지 테이블 heavy_ulid_pk와 heavy_ulid_sec 테이블을 만들어 100,000개 데이터를 삽입하여 결과를 비교하였다.
인덱스 발생 횟수나 소요시간은 heavy_ulid_sec의 경우에는 추가적인 인덱스를 사용하기 때문에 큰 의미가 없어 해당 지표는 비교 대상에 포함하지 않았다.
+---------------+----------------+------------+------------------+------------------------------+
| database_name | table_name | index_name | Total_Pages_Disk | Description |
+---------------+----------------+------------+------------------+------------------------------+
| index_test | heavy_ulid_pk | PRIMARY | 3626 | Number of pages in the index |
| index_test | heavy_ulid_sec | PRIMARY | 3622 | Number of pages in the index |
| index_test | heavy_ulid_sec | idx_ulid | 161 | Number of pages in the index |
+---------------+----------------+------------+------------------+------------------------------+
+----------------+----------------------+--------------------+
| TABLE_NAME | Pure_Data_Size_Bytes | Pure_Data_Size_MiB |
+----------------+----------------------+--------------------+
| heavy_ulid_pk | 59408384 | 56.66 |
| heavy_ulid_sec | 59342848 | 56.59 |
+----------------+----------------------+--------------------+
+------------------+------------+-----------------+--------------------------+----------------------+
| Pure_Table_Name | INDEX_NAME | Pages_In_Buffer | Real_Fill_Factor_Percent | Avg_Records_Per_Page |
+------------------+------------+-----------------+--------------------------+----------------------+
| `heavy_ulid_sec` | PRIMARY | 3578 | 90.5 | 15.0 |
| `heavy_ulid_pk` | PRIMARY | 2755 | 89.8 | 15.2 |
| `heavy_ulid_sec` | idx_ulid | 127 | 96.4 | 394.7 |
+------------------+------------+-----------------+--------------------------+----------------------+
테이블의 크기를 비교해보면, 레코드 내 다른 컬럼들의 크기가 크기 때문에 ULID 보조인덱스가 미치는 영향이 상대적으로 크지 않은 것을 알 수 있다.
핵심적으로 차이를 보이는 부분은 ‘페이지 당 평균 레코드 수’와 ‘총 페이지 수’이다.
주 인덱스의 Fill Factor는 Auto Increment한 값과 ULID 모두 순차성을 보이고 있기 때문에 약 90%의 좋은 결과를 보인다. 그러나, 레코드 자체의 크기가 크기 때문에 한 페이지당 평균 레코드 수가 15개로 매우 낮게 나온다.
보조 인덱스 idx_ulid의 경우에는 Fill Factor가 약 96.4%, 페이지 당 평균 레코드 수가 약 400개이다. 보조 인덱스는 논-클러스터링 인덱스로 (인덱스 키, PK)를 쌍으로 가지고 있기 때문이다.
즉, ULID를 PK로 사용하는 경우에는 한 페이지 당 레코드가 15개가 정도이기에, 레코드를 찾기 위해 3,626개의 페이지가 빈번하게 I/O 되는 일이 일어나게 된다.
그러나, 보조 인덱스가 존재하는 경우에는 한 페이지 당 400개의 레코드 PK를 가지고 있고 페이지 수가 161개 뿐이기에 I/O에 드는 비용 차이가 확실히 나타나게 된다. 당연하게도, 레코드의 크기가 크기 때문에 주 인덱스에서는 I/O 작업도 무겁다고 할 수 있다.
이를 기반으로 하여, 레코드 조회 시 성능 차이 여부를 확인해보고자 한다.
SET profiling = 1;
SELECT id FROM heavy_ulid_pk WHERE id LIKE '01J%';
SELECT sub_id FROM heavy_ulid_sec WHERE sub_id LIKE '01J%';
SHOW PROFILES;
mysql> SHOW PROFILES;
+----------+------------+------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+------------------------------------------------------------+
| 1 | 0.00638125 | SELECT id FROM heavy_ulid_pk WHERE id LIKE '01J%' |
| 2 | 0.00113025 | SELECT sub_id FROM heavy_ulid_sec WHERE sub_id LIKE '01J%' |
+----------+------------+------------------------------------------------------------+
ULID PK를 통하여 조회 쿼리를 실행한 결과는 6.38ms, ULID 보조인덱스를 통하여 조회 쿼리를 실행한 결과는 1.13ms가 소요된 것을 알 수 있다.
레코드 조회 시 약 5.64배 조회 속도 차이가 발생하게 된다.
mysql> EXPLAIN SELECT id FROM heavy_ulid_pk WHERE id LIKE '01J%';
+----+-------------+---------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | heavy_ulid_pk | NULL | range | PRIMARY | PRIMARY | 106 | NULL | 1 | 100.00 | Using where; Using index |
+----+-------------+---------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
mysql> EXPLAIN SELECT sub_id FROM heavy_ulid_sec WHERE sub_id LIKE '01J%';
+----+-------------+----------------+------------+-------+---------------+----------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------------+------------+-------+---------------+----------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | heavy_ulid_sec | NULL | range | idx_ulid | idx_ulid | 106 | NULL | 1 | 100.00 | Using where; Using index |
+----+-------------+----------------+------------+-------+---------------+----------+---------+------+------+----------+--------------------------
이는 당연하게도 조회 시 사용하는 인덱스가 보조 인덱스와 주 인덱스로 나뉘기 때문에 발생하는 차이이다.
위 결과를 바탕으로 ULID를 PK로 사용하는 경우 vs ULID를 보조 인덱스로 사용하는 경우를 비교한다면 다음과 같다.
레코드의 크기가 큰 실제 운영 상황에서는 하나의 레코드의 크기가 크기때문에 주 인덱스(클러스터링 인덱스)에서 페이지 당 레코드 갯수가 매우 적다.
보조 인덱스의 경우에는 논-클러스터링 인덱스로 페이지 당 보유 레코드 수가 주 인덱스 대비 많다. 또한, 페이지의 갯수도 적다. 따라서, 레코드 조회 시 주 인덱스보다 보조 인덱스를 사용하는 것이 더욱 효율적인 성능을 발휘한다는 것을 알 수 있다.
실제 운영 상황에는 레코드의 크기와 갯수, 보조 인덱스가 차지하는 비율 등을 잘 고려하여 적절한 방법을 선택해야 한다는 생각이 든다.
이번 테스트를 통하여 InnoDB 엔진의 페이지 분할 동작 방식과 운영체제의 페이지 교체 등의 개념들이 실제 데이터 삽입, 조회 시 영향을 미치는 직접적인 사례를 확인할 수 있었다. 또한, 인덱스라는 개념이 단순히 데이터를 빠르게 찾아주는 수단이 아니라 어떻게 구성되어 있으며, 어떠한 방법으로 사용해야지 효율적으로 사용할 수 있는지 배울 수 있었다.